수정 이력
2022.12.27
- 맞춤법 수정 및 참조 문제 항목 추가
서론
프로그래머스에서 다른 사람들의 코드를 보면 stream을 사용한 코드들을 종종 보는데
정석적인 방식에 비해 몇 배 느린데도 숏 코딩+ 간결해 보인단 이유로
좋아요를 꽤 받는 걸 보니 이렇게 짜는 게 정말 좋은 건지 궁금해서 알아보게 됐다.
정확한 속도 측정에 관해서는 Reference 항목의 3번째 링크의 동영상을 보면 된다.
https://programmers.co.kr/learn/courses/30/lessons/42578
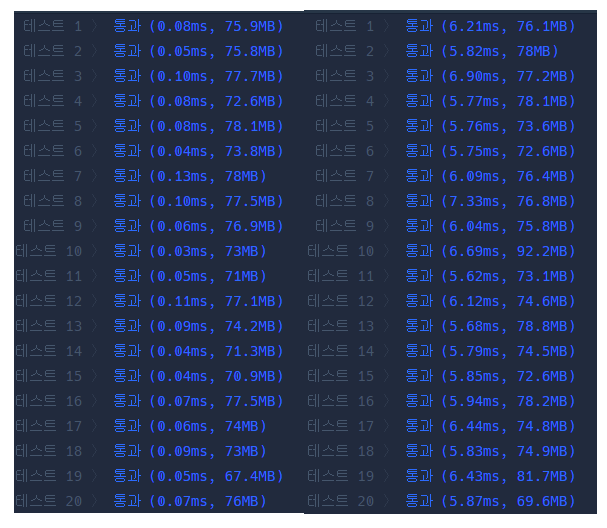
위 문제에서 stream을 사용하지 않을 때와 사용했을 때 속도 차이다.
왼쪽이 stream을 사용하지 않은 코드
오른쪽이 stream을 사용한 코드다.
stream이란?
java 8부터 나온 함수형 interface.
일련의 element 들에 대한 연산을 순차적, 또는 병렬적으로 처리해 준다.
다음 코드는 Widget 이란 객체에서 color가 "RED" 객체들의 weight의 합을 구하는 코드다.
기존 방식과 Stream 방식 둘 다 작성했다.
코드는 접어놨다.
더보기
import java.util.*;
public class Main {
static Widget[] widgets = {
new Widget("RED", 1),
new Widget("RED", 2),
new Widget("RED", 3),
new Widget("BLUE", 4)
};
public static void main(String[] args) {
old();
useStream();
}
// 기존 방식
public static void old() {
int sum = 0;
for(Widget widget : widgets) {
if(widget.getColor().equals("RED"))
sum += widget.getWeight();
}
System.out.println("old sum : " + sum);
}
// stream을 사용한 방식
public static void useStream() {
int sum = Arrays.stream(widgets)
.filter(w -> w.getColor().equals("RED"))
.mapToInt(w -> w.getWeight())
.sum();
System.out.println("useStream sum : " + sum);
}
}
class Widget {
private String Color;
private int weight;
public Widget(String color, int weight) {
Color = color;
this.weight = weight;
}
public String getColor() {
return Color;
}
public int getWeight() {
return weight;
}
}지금은 별 차이 없어 보이지만, 조건이 조금만 추가돼도 stream을 사용한 코드가 더 간결하다.
작동 방식
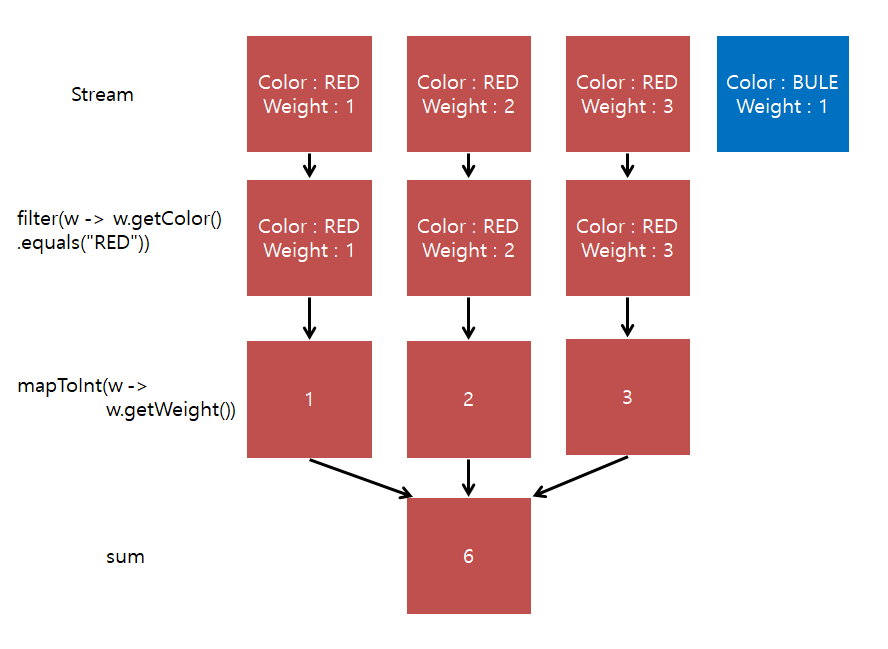
먼저, 각 element들은 하나의 Stream 형태로 구성돼 pipeline을 통해 전달된다.
(pipeline : 이전 process의 output이 다음 process의 input으로 이어지는 형태)
각 파이프라인들은 명시해놓은 연산을 수행 후 sum에서 이를 합친다.
위에 그림에서는 파이프라인을 화살표로 표시했다.
여기서 filter와 mapToInt 같은 연산들은 중간에 있단 의미로 intermediate 연산이라고 하며
각 intermediate 연산은 Stream을 반환한다.
sum과 같이 마지막에 위치하는 연산은 terminate 연산이라고 하며
Intermediate 연산을 모두 거친 Stream을 처리한다.
docs에선 이걸 consume이라 설명했다.
Stream의 특성
Stream은 자료 구조가 아니다. 따라서 저장 공간은 없다.
저장 공간이 없으므로, 재사용이 불가능하다.
만약 재사용을 하고 싶다면, pipeline을 통해 stream을 다시 전달한다.
즉, stream 다시 호출하면 된다.
stream은 terminate 연산을 마치면 그대로 끝난다. 즉, terminate된 stream은 다시 사용할 수 없다.
Stream은 원본 데이터에 영향을 주지 않는다. 필터나 수정을 거치면 거기에 맞는 stream을 반환하기 때문이다.
Intermediate 연산은 lazy 한, 특성이 있다. 결과가 필요하기 전 까진, 계산을 늦춘다.
위의 그림을 예시로 color 값이 RED가 아닌 객체들은 연산에 사용되지 않는다.
즉, 불필요한 연산을 하지 않는다.
Intermediate 연산은 stateless, stateful 2가지로 나뉜다.
stateless의 경우 filter나 map 같이 이전의 상태를 유지하지 않는다.
ex) 위 그림에서 filter를 거치게 되면 stream에서 color가 Blue인 객체는 빠진다.
ex) 위 그림에서 map을 거치게 되면 color 값은 사라지고 weight 값만 남는다.
stateful의 경우 이전의 상태는 유지시킨다.
ex) 여기엔 없지만 sort 연산의 경우 순서는 바꾸지만 전체적으로 보면 이전의 객체들은 그대로 있다.
그림으로 보면 다음과 같다.

반대로, terminate 연산은 eager 한 특성이 있다. 즉, Intermediate 연산에서 처리를 완료한 후, 반환된다.
iterator 같은 경우 예외라고 하는데 여기에 대해선 다루지 않는다.
왜 느릴까?
1. 최적화 문제
가장 큰 이유는 내부 최적화가 충분히 진행됐지 않았다는 것이다.
(reference 3번 링크의 영상에서 한 말)
충분히 납득되는 게, C를 예로 들자면
0 ~ 9까지 출력을 하는 loop를 만들고, 5가 되면 무조건 break 되는 loop.c 가 있다 할 때.
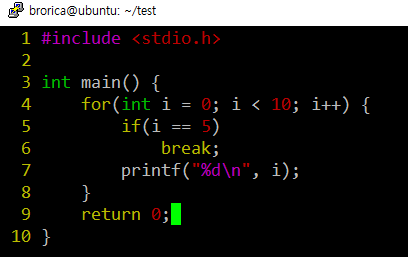
최적화되지 않은 어셈블리 코드 상태이다.
명령어 : gcc -O0 -std=c11 loop loop.c
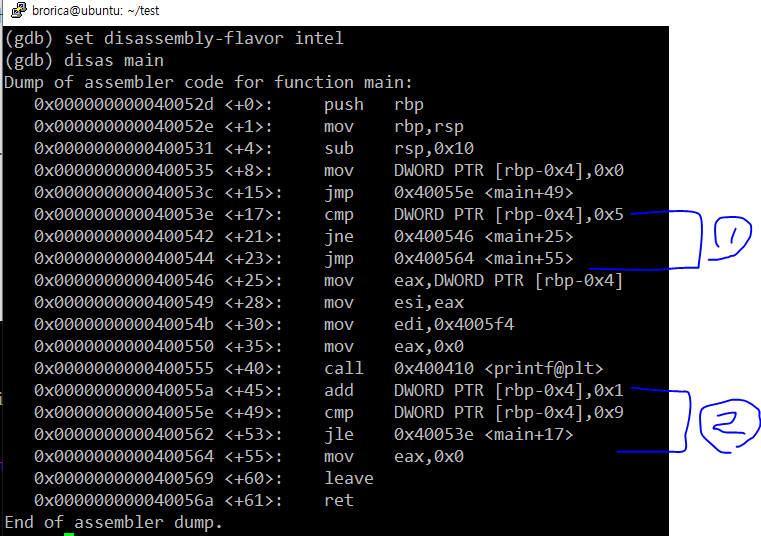
다른 거 볼 필요 없이 1번과 2번만 보면 된다.
1번은 우리가 작성한 i 가 5가 되면 break 하는 코드고
2번은 for 문에서 작성한 i < 10 과 i++ 해주는 코드다.
이제 이 코드를 최적화 한 어셈블리 코드다.
명령어 : gcc -O3 -std=c11 loop loop.c

최적화되기 전 어셈블리에선 5 하고도 비교하고 9 하고도 비교했는데
여기선 5가 되면 loop를 탈출하는 코드만 있다.
또한, i에 1을 더하는 코드도. printf 가 호출된 다음이 아닌, 호출되기 전으로 이동했다. ( +20 부분)
어차피 5가 되면 나가기 때문에 미리 1 더해 놓는 거라 보면 된다.
C는 오랜 기간 사용했던 언어인 만큼, 최적화도 그만큼 진행됐다.
JAVA 역시 오랜 기간 사용된 언어지만, Stream의 경우 비교적 최근에 나온 기능이기 때문에
Stream에 대해선 충분한 최적화가 진행되지 않았을 것이다.
2. 참조 문제

primitive 타입의 경우, 스레드 내부 스택에 있기 때문에 직접 접근이 가능하다.
하지만, Sream 인터페이스 경우, 제네릭 타입을 파라미터로 받고 있고, 파라미터는 클래스 형식이다.
따라서, primitive 타입의 경우 wrapper 클래스로 맞춰줘야 하고, 이렇게 되면 Heap 영역을 거치는 간접 참조가 된다.
또한, Heap 영역은 모든 스레드가 공유하기 때문에, 동시성 이슈로 락을 관리하는 경우도 있을 것이다.
즉, 접근하는 과정에서 부하가 발생할 수 있다.
보통 개발을 할 때, primitive 타입을 그대로 쓰기보단 커스텀 자료구조를 쓸 테니 이것이 근본적인 문제는 되지 않을 거라 생각한다. 다만, 자료구조가 단순한 코딩 테스트의 경우 불필요한 시간 복잡도가 발생할 수 있다.
stream을 쓰면 안 되나?
data source의 element 들에 대한 접근보다 한 element에 대한 연산이 많은 경우 유리하다.
즉, cpu intensive 한 연산의 경우 stream이 유리하다.
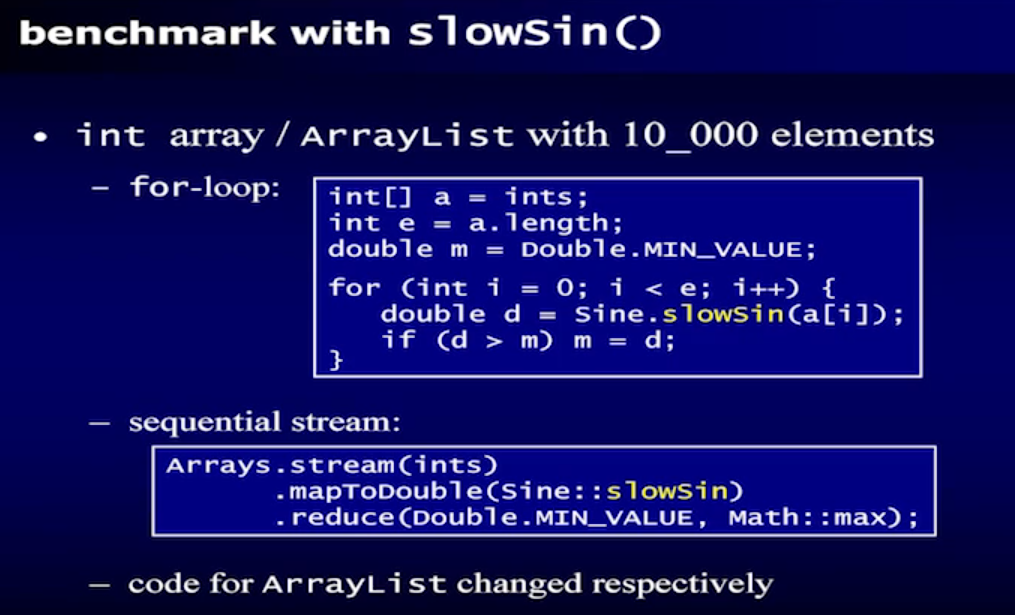
reference 3번 링크의 23분대에 SlowSin 이란 아무튼 연산이 복잡한 함수로 테스트를 했다.
결과만 loop와 stream에서 별 차이가 안 나는 것을 볼 수 있다.
영상의 일부만 가져왔기 때문에, 꼭 다 보는 것을 추천한다.

결론
1. Stream은 나온지 얼마 안 된 기능이기 때문에, 내부 최적화가 기존에 비해 부족하다.
2. 많은 element에 대해 접근이 많은 상황에선 array나 collection가 좋다.
3. collection의 경우 간접적으로 접근하기 때문에, stream보다 빠르긴 해도 array만큼 빠르진 않다.
4. 한 element에 대해 많은 연산이 필요한 경우 stream이 유리하다.
Reference
https://docs.oracle.com/javase/8/docs/api/java/util/stream/package-summary.html
https://www.oracle.com/technical-resources/articles/java/ma14-java-se-8-streams.html
'개발 > 자바' 카테고리의 다른 글
| [Java] 무지성으로 final 쓰지 않기 (0) | 2024.01.05 |
|---|---|
| 자바가 엔진단에서 어떻게 동작할까 (0) | 2023.12.30 |
| JPA 연관 관계에서 set과 list 차이 (2) | 2022.04.14 |
| Serialization (+ JPA) (0) | 2022.04.09 |
| 자바 gc 약한 세대 가설 (weak generational hypothesis) (0) | 2021.07.08 |
