들어가기 전에
오타나 잘못된 부분 지적은 언제나 환영입니다!
개인 PC에서 개발을 하고 성능 측정을 했기 때문에 백그라운드 프로그램으로 인한 변수가 있을 수 있습니다.
성능 측정에 대한 부분은 아직 미숙한 부분이 많습니다. 잘못된 측정에 관한 지적은 환영입니다.
발생한 문제
$ logN $의 시간 복잡도를 보장해야 할 R-Tree 인덱싱이 $ N^2 $의 시간 복잡도로 수행됐다.
처음엔 코드의 문제라 생각해 best practice 코드들과 비교했고
그 다음엔 다른 인덱싱 알고리즘들을 적용했다.
검색만으로는 문제를 해결하는 것이 불가능해 R-tree 코드를 분석한 결과 도로 데이터는 R-Tree 인덱싱 구성에 불리한 구조란 것을 알았다.
프로젝트 상황
dbms 버전 : PostgreSQL 13.5, PostGIS : 3.14
전국 데이터를 격자 형태로 나눈 사각형 좌표와 교차되는 도로 데이터를 찾아야 했다.
교차 검증에 대한 쿼리는 ST_Intersects를 사용했다.
그림으로 표현하면 아래와 같다.
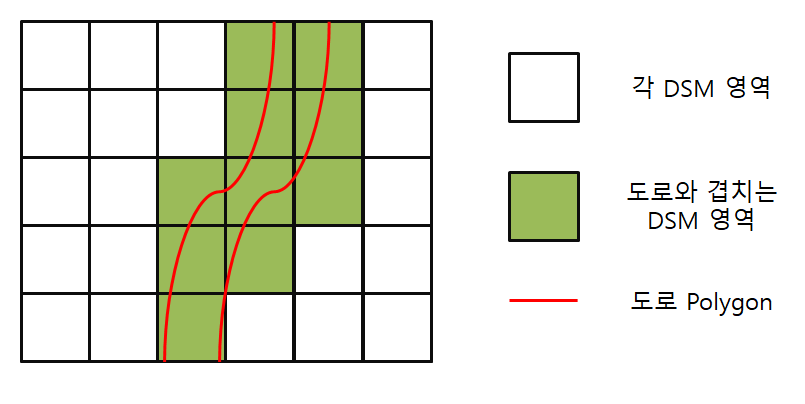
MultiPolygon 분리
처음엔 여러 Polygon으로 구성된 도로 정보 때문에 인덱싱에 필요한
MBR(minimum bounding rectangle) 영역이 지나치게 넓어져 속도가 느렸다고 생각했다.
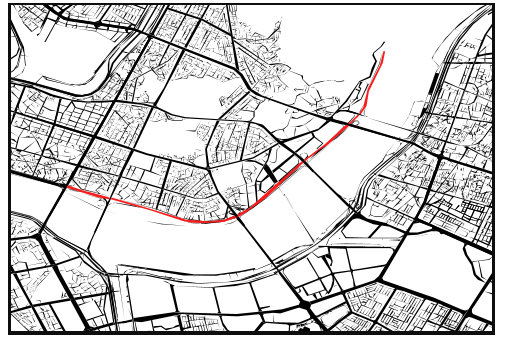

이 MultiPolygon을 분할한다면 인덱싱 트리를 더 효과적으로 구성할 수 있다 생각했다.
하지만, 생각보다 속도 개선이 이루어지진 않았다.
왜 안 됐을까?
R-tree는 아래 사진처럼 각 영역에 최소 단위의 사각형을 지정해 인덱싱 트리를 구성한다.
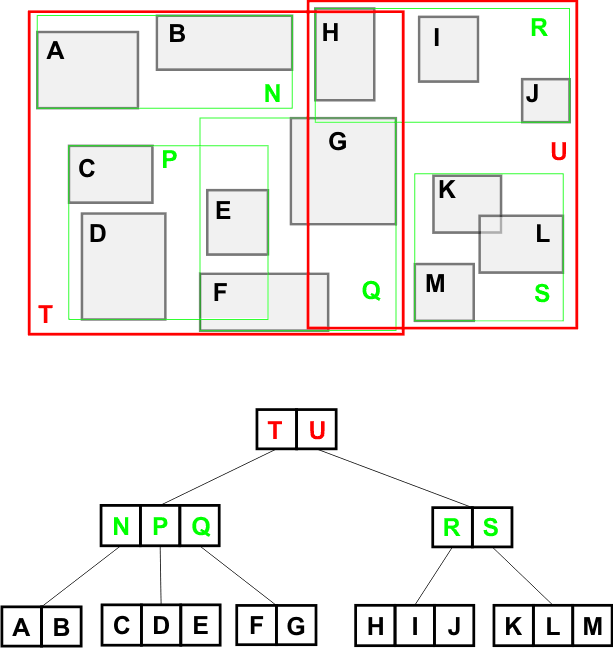
예시로 사용된 데이터들은 일정한 간격을 두고 떨어져 있기 때문에 이상적인 결과가 나온다.
하지만, 도로의 특징은 서로 이어져있다. 즉, 트리를 구성하는 과정에서 한 도로 데이터가 여러 노드 안에 들어가게 됐다.
아래 그림과 같이 무수히 많은 점들로 이루어진 도로 데이터가 있었고, 이런 데이터는 여러 인덱싱 노드에도 들어간다.
이러다 보니, 이전에 접근한 데이터를 다시 탐색하게 돼 시간 복잡도가 $ N^2 $ 로 뛰었던 것이다.
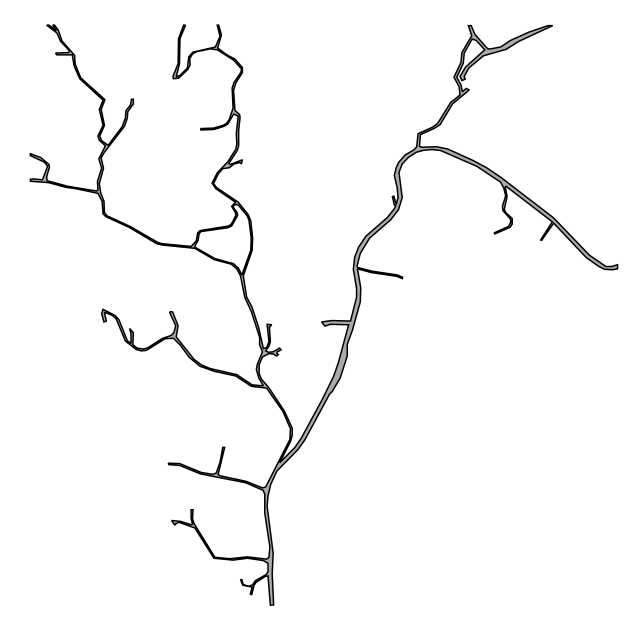
Polygon 내부 분할
각 도로는 서로 이어진 형태이기 때문에 여러 데이터가 겹치는 것은 피할 수 없었다.
그래서 겹치더라도 그 범위를 최소화하는 방향으로 결정했다.
그렇다면 데이터를 내부적으로 분할해야 하는데, 다행히도 PostGIS에서 제공하는 ST_SubDivide 쿼리를 통해 해결했다.
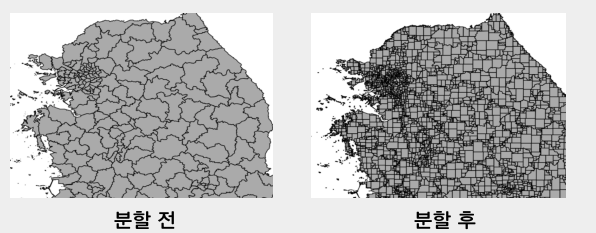
도로 데이터로 보여주긴 직관적이지 않았기 때문에
관련 데이터로 사용된 우리나라 시군구 경계 데이터를 분할한 결과를 예시로 하겠다.
성능 모니터
유난히 오래 걸렸던 지역들 중 한 곳에 대해 성능 모니터로 테스트를 했다.
https://docs.microsoft.com/en-us/previous-versions//cc768048(v=technet.10)?redirectedfrom=MSDN 를 참고했다.
개인 pc에서 측정했기 때문에, 성능과 다른 백그라운드 프로그램으로 인한 편차가 있을 수 있다.
그리고, 성능 시작과 중단을 직접 했기 때문에, 여기에 대한 오차도 존재한다.
측정한 키워드는 다음과 같다.
Memory : Page Faults/sec : 설명이 좀 어려운데 말 그대로 페이지 fault가 난 횟수로 이해했다.
Memory : Pages Input/sec : Page Faults와 함께 사용되며 Pages Input / Page Faults 을 통해 페이지 falut 백분율을 계산하는데 쓰인다.
Memory : Page Reads/sec : page fault가 일어날 때 디스크에 읽는 빈도 계산
Memory : Page Output/sec : 메모리의 수요가 증가하면서 다른 응용 프로그램을 디스크 단으로 스왑 아웃 하는 과정에서 생기는 페이지 수
Memory : Cache Faults/sec : 초당 캐시 미스
Processor : % Processor Time : 프로세서가 수행한 시간
인덱싱만 했을 때
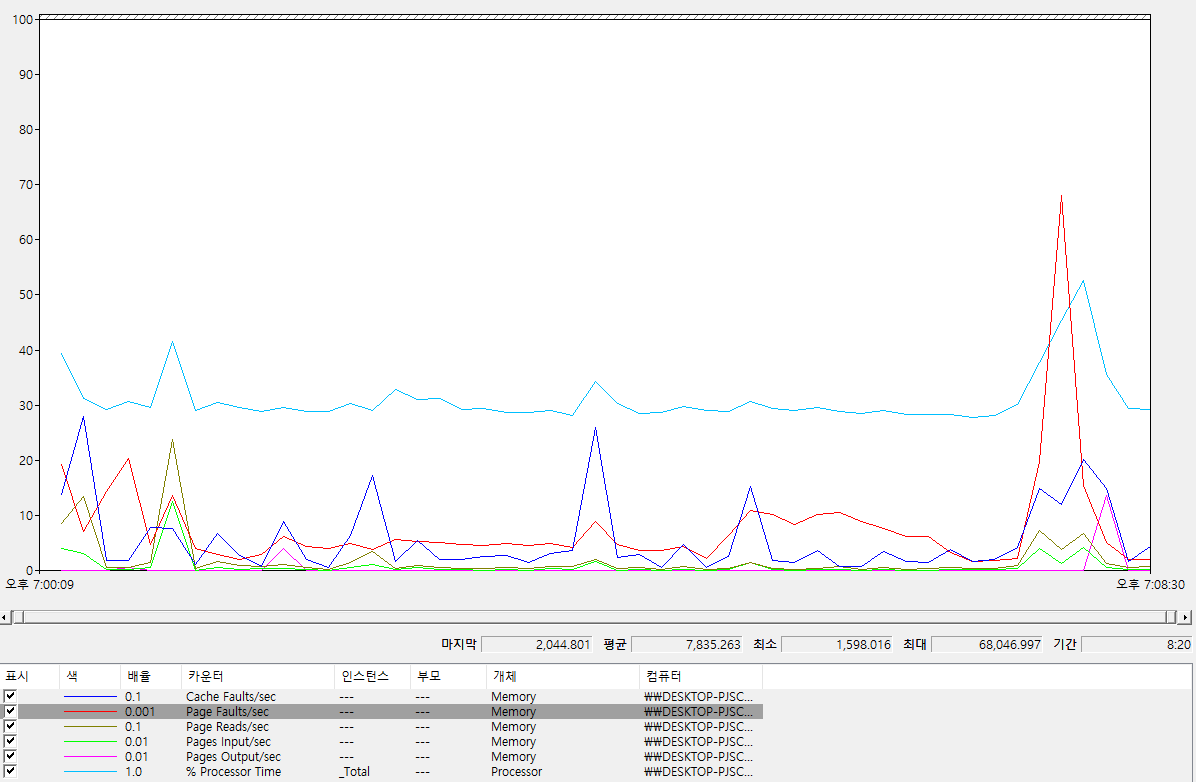
Memory : Page Faults/sec : 평균 7,835.263
Memory : Pages Input/sec : 평균 82.505
Memory : Page Reads/sec : 평균 19.064
Memory : Page Output/sec : 평균 36.432
Memory : Cache Faults/sec : 평균 56.173
Processor : % Processor Time : 평균 30.994
인덱싱 + 내부 Polygon 분할
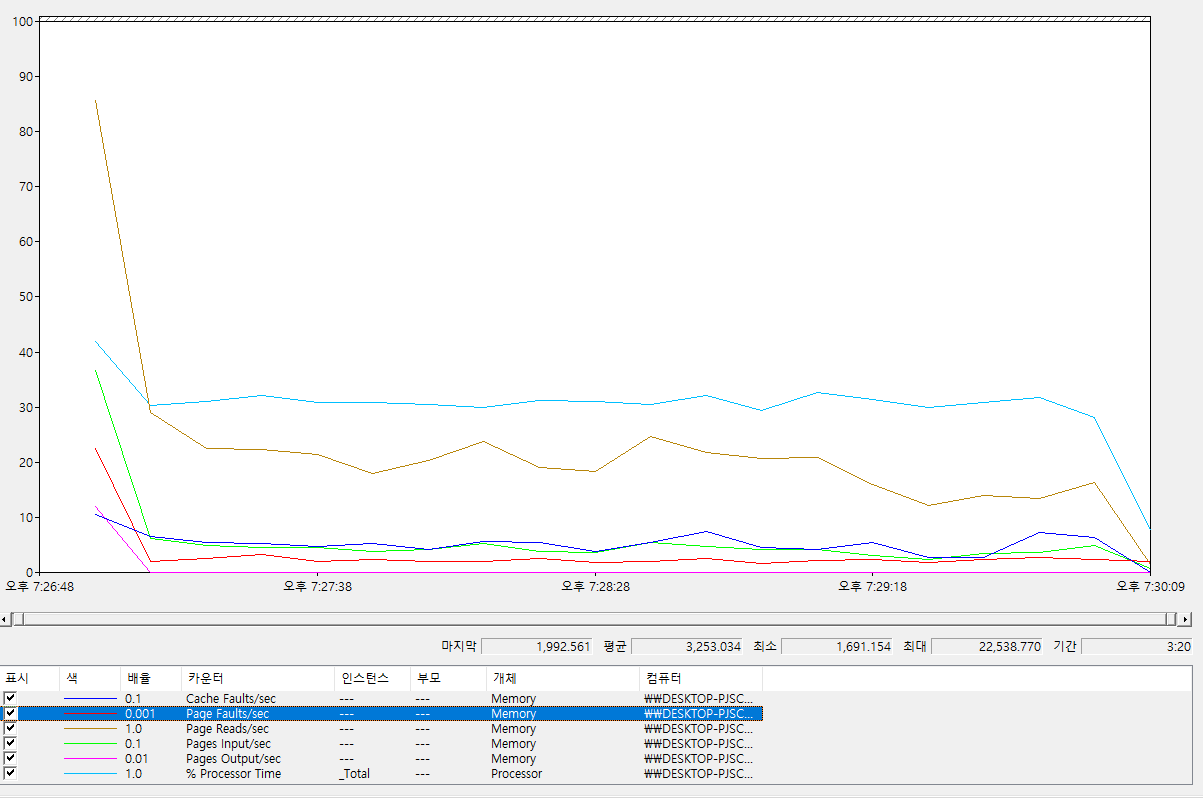
Memory : Page Faults/sec : 평균 3,253.034
Memory : Pages Input/sec : 평균 57.028
Memory : Page Reads/sec : 평균 22.074
Memory : Page Output/sec : 평균 59.613
Memory : Cache Faults/sec : 평균 51.633
Processor : % Processor Time : 평균 30.213
종합해보면, 공간 쿼리의 연산량 감소 뿐만 아니라, 데이터를 찾기 위한 인덱싱 과정에서 탐색하는 페이지 수도 그만큼 감소했다.
또한, 맨 처음에 값이 튀는 부분을 제외하고 본다면 기록된 수치보다 더 좋은 성능을 보인다.
마치면서
해결한 문제의 코드 자체는 굉장히 간결했지만, 그 결과에 이르기까지는 상당한 노력이 필요했다.
보통 How to ~ 또는 ~ not working 같이 구글 첫 페이지에서 해결책을 찾는 것에 익숙했다. 하지만 그런 방법으로 해결할 수 없는 문제를 만나니 무척 당황스러웠다.
그럼에도 불구하고, 문제를 정의하고, 해결 방안을 제시하는 경험을 할 수 있었다. 이런 경험을 통해, 검색만으로 해결하기 어려운 문제를 만났을 때 좀 더 자신감을 갖고 문제에 접근할 수 있게 됐다.
Reference
https://bartoszsypytkowski.com/r-tree/
R-Tree: algorithm for efficient indexing of spatial data
B+Trees are one the most common structures in the database world, especially in a context of indexing. They map well onto a page/block model used for persisting data on the hard drives and provide a nice "jack of all trades" route between capabilities (eg.
bartoszsypytkowski.com
'개발' 카테고리의 다른 글
| redis 1.0 분석 - 공유 메모리 풀 (0) | 2023.11.30 |
|---|---|
| 초기 Redis 분석 - 이벤트 루프 (0) | 2023.11.24 |
| 초기 Redis 분석 - 자료구조 (0) | 2023.11.22 |
| Uber H3 - 육각형 계층의 공간 인덱스 (2) | 2022.12.23 |
| Uber H3을 적용해 좌표 데이터 용량 20배 줄이기 (0) | 2022.12.17 |



