들어가기 전에
프로젝트 도메인 특성상 자주 마주할 것이라 생각해 나에게 필요해 보이는 것들 위주로 정리했다.
짧게 요약하면
1. 이진 데이터를 다루지만 자료형이 없다.
2. ArrayBuffer은 고정 크기, Blob은 가변 크기
3. ArrayBuffer를 통해 Blob 불변 객체를 만들 수 있다.
문제 상황
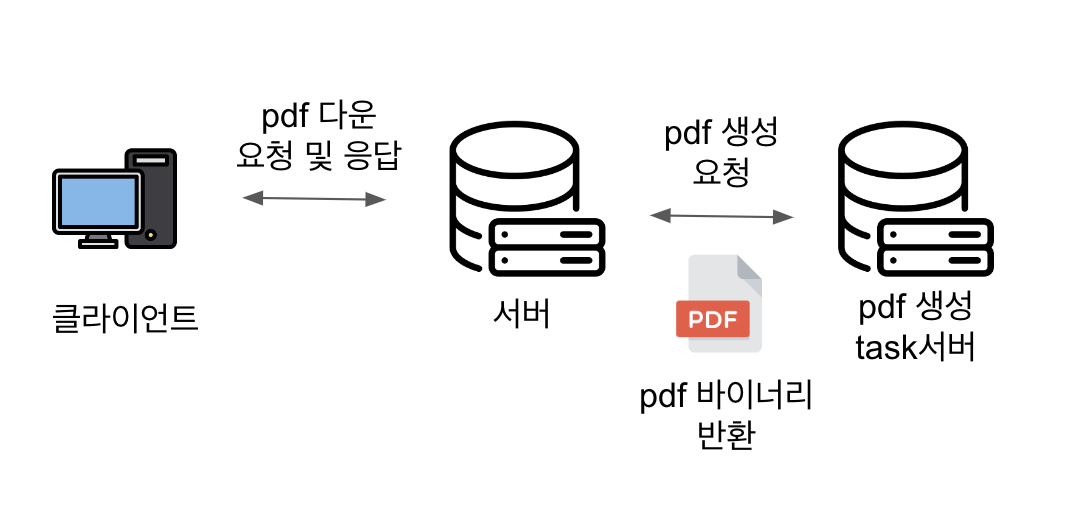
pdf 다운로드 기능 구현 도중 인코딩 이슈가 발생해 pdf 쪽수는 맞는데 빈 페이지만 보여주는 문제가 있었다.
task 서버에서 바이너리를 인코딩을 안 해서 생긴 문제였지만,
검색 과정에서 arrayBuffer와 Blob을 알게 됐고, 둘이 어떤 차이인지 궁금해 정리하게 됐다.
관련 stackoverflow
https://stackoverflow.com/questions/34436133/pdf-is-blank-when-downloading-using-javascript
PDF is blank when downloading using javascript
I have a web service that returns PDF file content in its response. I want to download this as a pdf file when user clicks the link. The javascript code that I have written in UI is as follows: $h...
stackoverflow.com
ArrayBuffer는 배열이 아니다
배열은 번호(인덱스)와 번호에 대응하는 데이터들로 이루어진 자료 구조를 나타낸다.
데이터의 연속된 집합은 맞지만, 특정 인덱스를 가리킬 때 데이터를 얼마나 끊을지 모르기 때문이다.
ArrayBuffer에서 인덱스를 지정하면 거기에 매칭되는 데이터 주솟값을 모르기 때문이다.
C 기준으로 int형 배열에서 인덱스 1 증감하면 자료형이 int형란 것을 알기 때문에 컴파일러가 4바이트씩 데이터 주솟을 증감하지만,(int 크기는 4byte로 정한다.)
ArrayBuffer는 자료형이 없기 때문에 인덱스에 대응되는 데이터 주솟값을 모른다.
이를 해결하기 위해 Uint8Array, Uint16Array 같은 TypeArray를 사용해 8비트씩, 16비트씩 데이터를 구분한다.
(인코딩 바꾸면 영어가 중국어나 한글로 보이는 원리)
Blob 역시 우리가 아는 배열처럼 쓰기 위해선 TypeArray를 써야 한다.
Blob은 불변이다.
반면, ArrayBuffer은 자신이 할당받은 주솟값이 변하지 않지만, 내부 데이터가 변경될 수 있다.
다음 예시 코드를 통해 ArrayBuffer의 내부 데이터를 변경할 수 있다.
// 8바이트의 ArrayBuffer 생성
const buffer = new ArrayBuffer(8);
// let buffer = 3; // Error: Identifier 'buffer' has already been declared
// Uint8Array를 사용하여 ArrayBuffer에 대한 뷰를 생성
const view = new Uint8Array(buffer);
// 초기 데이터 설정
view[0] = 1;
view[1] = 2;
view[2] = 3;
console.log('초기 데이터:', view); // 초기 데이터: Uint8Array(8) [1, 2, 3, 0, 0, 0, 0, 0]
// 데이터 수정
view[0] = 10;
view[1] = 20;
console.log('수정된 데이터:', view); // 수정된 데이터: Uint8Array(8) [10, 20, 3, 0, 0, 0, 0, 0]Blob()에서 String은 UTF-8로 인코딩한다.
개발 단계에서 주요 이슈가 파일의 인코딩이 항상 UTF-8인 것이었다.
글 쓰면서 찾아보니 Blob에서 String 타입은 UTF-8로 인코딩된다고 한다.(레퍼런스 확인의 중요성)
File은 Blob 서브 인터페이스
처음엔 파일을 다루는 거니 File 관련 키워드가 나와야 하나 싶었다.
Blob이 데이터를 불변 상태로 만들면 File 같이 불변 데이터를 취급하는 객체들이 Blob을 상속받는다.
그래서 콘솔로 찍어보면 size와 type만 나오지만 File 데이터는 파일명 같은 메타데이터까지 나온다.
Blob.slice()에 대한 궁금증
큰 파일이 사용될 때, 대역폭 문제로 업로드나 다운로드를 조금씩 진행할 상황이 있다 생각했다.
이때, 인터럽트나 네트워크 딜레이 등으로 데이터 청크가 늦게 도착한 경우, 어떻게 청크들의 순서를 파악하고 조합할 수 있는지 궁금했다.
내 기준 참고할 만한 케이스는 찾지 못했지만, 여기에 대해 웹 워커(Web Worker)란 기술을 알게 됐다.
깊이 있게 찾아보는 건 지금 여기서 다루긴 지엽적이라 JS에서 별도의 멀티 스레드로 수행한다 정도만 알고 넘어가려 한다.
URL.createObjectURL()
document 내에서만 유효한 객체 URL을 생성한다.
창 닫기 같은 document 해제 작업 시, 해당 URL은 못쓰게 된단 점에서 보안성이 좋다.
외부 접근이 가능한 사이트에서 민감한 파일을 다룬다면 사용하게 될 것 같다.
하지만, URL.revokeObjectURL()를 호출해 메모리에서 해제한다는 것을 보아
해당 URL을 못쓰게 한단 거지, 메모리에는 상주하는 것 같다.
C 기준으로 생각하면, 함수에서 동적 배열 해제 안 하고 반환한 상황이라 생각한다.
Reference
https://www.w3.org/TR/FileAPI/#slice-method-algo
https://developer.mozilla.org/ko/docs/Web/API/Blob
https://developer.mozilla.org/en-US/docs/Web/API/File
https://developer.mozilla.org/ko/docs/Web/API/Web_Workers_API
'개발' 카테고리의 다른 글
| 파일 옮길 땐 tar를 쓰자 (0) | 2024.11.19 |
|---|---|
| 단위 테스트 적용하기 (0) | 2024.10.26 |
| [Java] p6spy 긴 바인딩 로그 치환하기 (0) | 2024.09.04 |
| [python] pandas csv 분할 중 .0 .1 문제 (0) | 2024.08.29 |
| proxyBeanMethods=false를 써야 하는지 (0) | 2024.07.21 |

