목차
- 서론
- 물리 cpu vs 논리 cpu
- 사용 시간, 경과 시간
- 컨텍스트 스위치
- 스레드 vs 프로세스
- 처리 성능
- 결론
- Reference
서론
이번 장에선 os 상에서 여러 개의 프로세스가 어떻게 실행되는지 설명한다.
프로세스가 어떻게 자원을 점유하는 과정을 테스트 코드를 통해 확인하고
이전 장에서 배운 프로세스 관련 명령어들을 이용해 상태를 확인할 수 있다.
물리 cpu vs 논리 cpu
이 책을 보면 논리 cpu라는 용어가 많이 나오는데 둘의 차이가 궁금해 정리했다.
- 물리 cpu: 실제 프로세스 개수
- 논리 cpu: 물리 프로세스 하나가 동시에 처리할 수 있는 작업 수
lscpu를 통해 물리, 논리 cpu를 확인할 수 있다.
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 39 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
Vendor ID: GenuineIntel
Model name: Intel(R) Core(TM) i5-4690 CPU @ 3.50GHz
CPU family: 6
Model: 60
Thread(s) per core: 1
Core(s) per socket: 4
Socket(s): 1
- CPU(s): 논리 코어. i5라 4개를 가지고 있다.
- Thread(s) per core: 코어당 스레드 수. 가상 환경이라 1개이다.
- Core(s) per socket: 소켓에 장착된 코어 수. i5라 4개의 코어를 가지고 있다.
- Socket(s): 가정용 메인보드에서 cpu 꽂는 자리 보통 1개다.
하이퍼 스레딩 기술을 이용하면 물리 cpu 하나가 2개의 논리 cpu처럼 동작하게 할 수 있다.
내 cpu는 하이퍼 스레딩을 지원하지 않아, 논리 cpu가 8개가 아닌 4개이다.
사용 시간, 경과 시간
- 경과 시간: 프로세스 시작 ~ 종료까지 시간
- 사용 시간: 프로세스가 실제로 논리 CPU를 사용한 시간
다음 코드를 time 명령어로 실행한 결과다.
예시 코드
#!/usr/bin/python3
#load.py
#부하 정도를 조절하는 값
#time 명령어를 사용해서 실행했을 때 몇 초 정도에 끝나도록 조절하면 결과를 확인하기 좋음
NLOOP = 100000000
for _ in range(NLOOP):
pass
실행 결과
$ time ./load.py
real 0m2.862s
user 0m2.850s
sys 0
time 명령어의 결과들에 대한 설명이다.
- real: 경과 시간
- user: 사용자 공간에서 동작 시간
- sys: 커널이 동작한 시간
위의 코드는 시스템 콜 없이, 루프만 수행해서 sys 시간은 0으로 집계된다.
컨텍스트 스위치
문맥 교환이라고도 한다.
프로세스가 실행 중에 다른 프로세스로 작업을 전환하는 행위다.
한 프로세스가 불필요하게 cpu 자원을 선점하는 것을 막는 역할도 한다.
다음 상황에서 컨텍스트 스위칭이 발생한다.
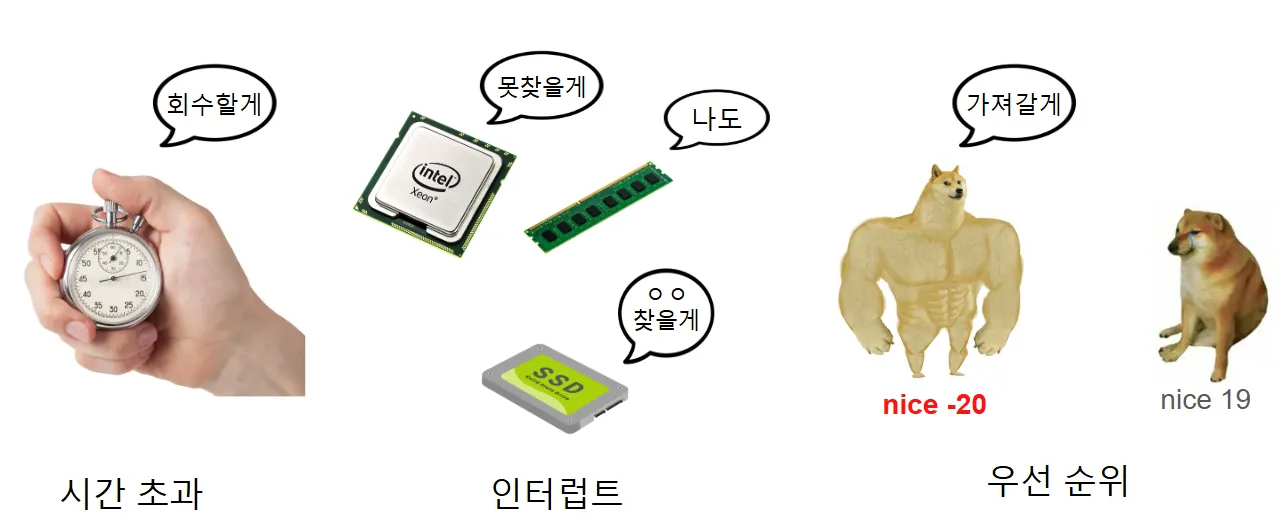
- 시간 초과: 할당된 cpu 시간을 모두 사용한 경우 ex) 라운드 로빈
- 인터럽트: I/O 작업이 발생 ex) 메모리 폴트로 인한 디스크 탐색, 네트워크 통신
- 우선순위: 선점형 스케줄링(Preemptive Scheduling) 기법에서 우선순위가 높거나, lock이 걸린 상황에서 os가 자원을 회수해 다른 프로세스에게 할당
밑에 설명하겠지만, 스레드 역시 프로세스와 동일한 상황에서 문맥 교환이 발생한다.
스레드 vs 프로세스
문맥 교환은 프로세스 내의 스레드 간에서도 발생한다.
프로세스보다 더 적은 정보를 갖고 있기 때문에 문맥 교환 비용은 스레드 < 프로세스다.
문맥 교환시, 프로세스와 스레드는 각자의 메타 데이터를 교체하고
스레드는 TCB(Thread Control Block), 프로세스는 PCB(Process Control Block)을 교체한다.
TCB 구성은 다음과 같다.
1. tid: 스레드 ID
2. 스택 포인터: 함수 포인터 기준 스택이 어느 정도 떨어져 있는지 ex) esp, rsp 레지스터
3. 프로그램 카운터: 현재 실행 중인 명령어 위치 ex) PC, EIP, RIP 레지스터
4. 기타 스레드 레지스터: ex) RAX, RBX 등
5. 스레드 상태: 생성 / 실행 / 대기 / 종료
6. 스레드가 존재하는 프로세스 제어 블록(PCB)에 대한 포인터
PCB 구성은 다음과 같다.
1. 프로세스 식별 정보: PID / 부모 PID / 사용자 ID(UID) / 그룹 ID(GID)
2. 프로세스 상태: 생성 / 실행 / 대기 / 종료
3. 프로그램 카운터: 현재 실행 중인 명령어 위치 ex) PC, EIP, RIP 레지스터
4. 기타 스레드 레지스터: ex) RAX, RBX 등
5. 메모리 주소 정보: .text / .data / heap 등 메모리 영역 offset
6. 스케줄링 정보: 우선 순위 및 cpu 할당 정보(time slice)
7. 파일 정보: File Descriptor
처리 성능
- 처리 시간(턴어라운드 타임): 프로세스의 요청이 끝나기까지 걸린 시간
- 프로세스가 증가하면 번갈아가면서 쓰기 때문에 시간이 더 걸린다.
- 스루풋: 단위 시간당(우리가 정함) 종료되는 프로세스 수
- 처리 지표로 MB/s, IO/s 가 있다.
- 응답 성능이 중요한 환경에서 주요 지표
논리 CPU가 감당할 수 있는 선에선 처리 시간만 느려지지만,
프로세스가 많아 컨텍스트 스위치 비중이 커진다면, 스루풋도 같이 떨어진다.
정리하면, 스루풋 향상을 위해선 논리 CPU와 프로세스 개수 간의 선타기가 필요하다.
다른 글을 통해 확인한 결과 스루풋은 다양한 영역에서 쓰이고 지표는 다음과 같다.
- 네트워크: MB/s
- 스토리지: IO/s
이 둘이 나뉘는 이유는, 네트워크에선 대역폭 사용량이 중요하지만
스토리지에선 I/O 작업을 얼마나 많이 수행할 수 있는지가 중요하지, 큰 Block을 잘 처리하는 것은 큰 의미가 없다고 이해했다.
따라서, 대역폭 검증(MB/s)을 마쳤다면 스토리지는 I/O 작업을 얼마나 처리할 수 있는지를 보는 것이 더 확실한 지표를 얻을 수 있다고 한다.
결론
이번 장에선 프로세스 스케줄링과 관련된 개념인 컨텍스트 스위치, 처리 시간에 대해 공부했다.
어떤 상황에서 컨텍스트 스위치가 발생하고, 예제 코드를 통해 처리 성능 간 지표를 분석해 처리시간과 스루풋 간의 상관관계를 확인했다.
이를 통해 운영 환경에서 CPU 자원을 효율적으로 쓸 수 있는 방법 중 하나를 알게 됐다.
Reference
https://www.geeksforgeeks.org/context-switch-in-operating-system/
https://en.wikipedia.org/wiki/Thread_control_block
https://www.geeksforgeeks.org/process-table-and-process-control-block-pcb/?ref=lbp
'개발' 카테고리의 다른 글
| nohup 코드 분석 (1) | 2025.06.01 |
|---|---|
| 그림으로 배우는 리눅스 구조 4주차 (1) | 2025.04.10 |
| 그림으로 배우는 리눅스 구조 2주차 (0) | 2025.03.29 |
| 그림으로 배우는 리눅스 구조 1주차 (0) | 2025.03.16 |
| [JPA] FindAll이 같은 값만 나와요 (2) | 2025.02.15 |



