가상의 명령어를 실행하는데 몇 바이트가 드는지 계산해본다.
가산기, 레지스터 등 CPU 내부에 기억장치가 없는 메모리 - 메모리 컴퓨터 구조이다.
모든 데이터가 CPU를 경유해 메모리로 전송되기 때문에,
명령어의 피연산자 필드엔 메모리 전체 주소를 명시해야 한다.
메모리-메모리 컴퓨터
구성은 다음과 같다.
연산 부호 8비트, 즉 1바이트
연산마다 최대 2개의 피연산자
첫 번째 피연산자는, 목적지 겸용 (Z = Z + X)
메모리 주소는 16비트, 즉 2바이트
데이터 크기는 32비트, 즉 4바이트 (1워드)
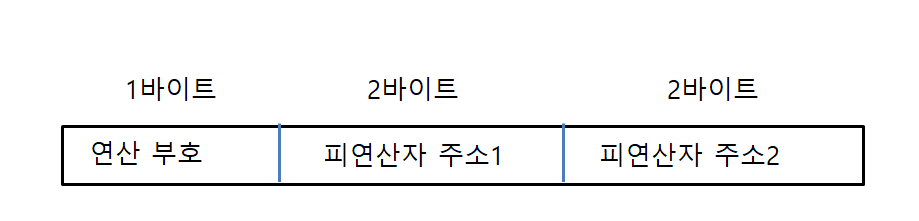
명령어는 2^8개인 256개이고,
데이터는 2^32의 수를 다룰 수 있고,
메모리는 2^16워드 용량의 메모리 사용 가능
다음과 같은 명령어 집합이 있다 하자.
MOV y, a
MUL y, x
MUL y, x
MOV t, b
MUL t, x
ADD y, t
ADD y, c
여기선 7개의 명령어가 있고,
명령어 인출 사이클은
7 * (1 + 2 + 2) = 35 바이트가 발생한다.
실행 트래픽은
mov 명령어에서 mov y, a는
a번지에 데이터를 CPU로 가져와 메모리 y에 저장하는 뜻이다.
따라서, a번지 데이터는 CPU로 이동, 메모리로 이동
즉, 2번의 데이터 이동이 일어나므로 8바이트 트래픽이 발생한다.
ADD와 MUL은
두 개의 피연산자를 CPU로 가져와 목적지 주소로 저장을 해야하기 때문에,
두 개의 피연사자를 CPU로 가져오는 작업 2번, 메모리로 이동
즉, 3번의 데이터 이동이 일어나므로 12바이트 트래픽이 발생한다.
정리하면 실행 사이클은 (8 * 2 + 12 * 5 ) = 76 바이트의 트래픽이 발생한다.
그러므로 이 명령어 집합은 76 + 35 = 111 바이트의 트래픽이 발생한다.
물론 여기서 레지스터, 가산기, 스택 등을 사용하면 더 절약할 수 있다.
ACC 컴퓨터
이제 이 방식은 안 쓰지만, 중간 단계를 보기 위해 넣었다.
ACC는 데이터를 저장하기 위한 레지스터이기 때문에,
데이터 2개 불러올 걸 1개로 줄일 수 있다.
그렇게 되면 명령어 구성은 다음과 같다. 메모리 주소는 여전히 4바이트다.

메모리보다 레지스터의 크기가 더 크므로,
mov 연산을 사용할 수 없어, 주소 관련 명령어인 LDA, STA을 사용한다.
명령어 집합은 다음과 같다.
LDA A // ACC = 메모리[A]
MUL X // ACC = 메모리[A] * 메모리[X]
MUL X // ACC = 메모리[A] * 메모리[X]^2
STA Y // Y = ACC
LDA B // ACC = 메모리[B]
MUL X // ACC = 메모리[B] * 메모리[X]
ADD C // ACC = 메모리[B] * 메모리[X] + 메모리[C]
ADD Y // ACC = 메모리[A] * 메모리[X]^2 + 메모리[B] * 메모리[X] + 메모리[C]
STA Y // Y = ACC
인출 사이클부터 보자.
각 명령어당, 피연산자가 하나만 요구되니, 3바이트의 트래픽이 발생하니,
3 * 9 = 27 바이트 트래픽이 발생한다.
실행 사이클은, 데이터 주소 인자가 명령어당 1개씩 밖에 없으니,
4 * 9 = 36바이트 트래픽이 발생한다.
합해서 53 바이트가 나온다.
위의 메모리-메모리 컴퓨터 구조에 비해 50% 이상 트래픽 절약을 할 수 있다.
스택 컴퓨터
CPU 내부에 다수의 데이터를 임시러 저장하기 위해 스택을 사용한다.
대부분 연산은 스택의 최상위, 차상위 데이터를 사용하여 수행한다.
즉, 명령어는 스택 최상위에 위치한 1~2개 데이터를 묵시적 피연산자로 사용 가능
최근 연산한 데이터는 스택의 최상위에 배치된다.
데이터 주소가 여전히 4바이트란 가정 하에, 데이터 형식은 다음과 같다.
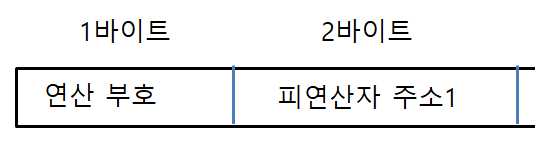
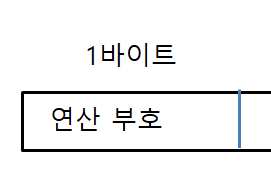
명령어 집합은 다음과 같다.
PUSH A // TOS = A
PUSH X // TOS = A, X
PUSH X // TOS = A, X, X
MUL // TOS = A * X
MUL // TOS = A * X * X
PUSH B // TOS = B, A * X * X
PUSB X // TOS = B, X, A * X * X
MUL // TOS = B * X, A * X * X
PUSH C // TOS = TOS = C, B * X, A * X * X
ADD // TOS = C + B * X, A * X * X
ADD // TOS = C + B * X + A * X * X
POP Y // Y = TOS
// TOS : TOP OF STACK 스택 최상단
인출 사이클을 보면,PUSH, POP 명령어는 피연산자가 요구되니 3바이트의 트래픽이 발생하고,MUL, ADD 명령어는 피연산자가 없어서 1바이트의 트래픽이 발생한다.즉, 인출 사이클은 3*7 + 1*5 = 26 바이트 트래픽이 발생한다.
실행 사이클은PUSH, POP 에서만 데이터의 이동이 발생하니4 * 7 = 28 바이트 트래픽이 발생한다.
누산기 컴퓨터보다 좋은 성능을 내지만, 상황에 따라서 누산기 컴퓨터가 더 좋을 수 있다.
범용 레지스터 컴퓨터
CPU 내부에 다수의 데이터를 임시로 저장하기 위해
범용 레지스터를 사용하는 컴퓨터이다.
여 컴퓨터는 16개의 레지스터를 사용할 수 있다.(2^4 = 16, 4비트 크기)
메모리에 접근하지 않고, 바로 사용할 수 있어서 데이터 트래픽이 발생하지 않는다.
데이터 형식은 다음과 같다.


명령어 집합은 다음과 같다.
load r1, x
load r2, a
load r3, b
load r4, c
mul r2, r1
mul r2, r1
mul r3, r1
add r3, r2
add r4, r3
store r4, y
인출 사이클은
load, store 명령어는 연산부호 1바이트, 레지스터 0.5바이트, 메모리 주소 2바이트를 사용한다.
즉, 각 명령어는3.5바이트의 트래픽이 발생한다
하지만, 컴퓨터의 최소 단위 정보는 바이트 단위이므로 4바이트 트래픽이 발생한다.
그 외 명령어는, 1개의 연산부호, 2개의 레지스터를 사용하므로,
2바이트의 트래픽이 발생한다.
즉, 인출 사이클은 4 * 5 + 2 * 5 = 30바이트의 트래픽이 발생한다.
메모리에 접근하는 일이 없으므로, 데이터 트래픽이 일어나지 않기 때문에,
실행 사이클은 트래픽이 발생하지 않는다.
얼핏 보면, 범용 레지스터 컴퓨터가 훨씬 좋아보이지만 다음 문제가 있다.
레지스터가 너무 많단 가정하에
1. 레지스터 주소가 길어져서 명령어 길이도 늘어난다.
2. 컴파일러가 모든 레지스터를 사용하기 어렵다.
3. 많은문맥 교환 비용이 발생한다.
4. 하드웨어 비용 상승
출처 : 컴퓨터 아키텍처 컴퓨터 구조 및 동작 원리 (한빛 아카데미)
'학교 > 컴퓨터 구조' 카테고리의 다른 글
| 5. 데이터 경로 (1/4) 개요 (0) | 2020.12.02 |
|---|---|
| 4. 명령어 집합 (2/2) 주소 지정 방식 (0) | 2020.11.30 |
| 3. 컴퓨터의 성능 (3/4) 연산 (0) | 2020.11.30 |
| 3. 컴퓨터의 성능 (2/4) CPU의 기본 구성과 명령어 집합 (0) | 2020.11.30 |
| 3. 컴퓨터의 성능 (1/4) 명령어 집합 (0) | 2020.11.30 |
