Database 에 문제가 발생하면, 마지막으로 성공한 작업으로 돌아감(consistent state)
system log는 이런 상황을 대비해, 트렌젝션들에 의해 변경된 data 정보 기록
하지만, 메인 메모리에 대한 정보는 잃음
Recovery 방법엔 크게 2가지가 있다.
1. catastrophic failure
- 백업된 다른 archival stoarge로 복구
- 백업된 로그에서, 커밋된 트렌젝션 작업을 실패 지점까지 돌리거나, 다시 실행해 최신 상태 재구성(redo)
2. noncatastrophic failure
- 데이터베이스에서 inconsist를 유발할 수 있는 변경 사항 파악
- 디스크에서 완전히 커밋되지 않은 트렌젝션은 처음부터 다시 해야 함(undo)
- 일관성 유지를 위해, 작업을 다시 할 수도 있음(redo)
- 다음 2가지 정책이 있다.
1. deferred update : 지연 업데이트
-> 밑에서 볼 no-steal, no-force이 여기에 해당
2. immediate update : 즉시 업데이트
-> 밑에서 볼 steal, force 방식이 여기에 해당
Caching(Buffering) of Disk blocks
복구 절차의 효율을 위해 디스크 페이지 캐싱은 OS가 아닌, DBMS가 처리
버퍼 교체
dirty bit : 버퍼의 수정 유무를 명시 수정 안 됐으면, 버린다(flush)
pin-upin bit : 캐시의 페이지의 사용 유무 표시. pin이면 사용중이니, flush 하면 안 된다.
버퍼를 flush 하는데엔 2가지 정책이 있다.
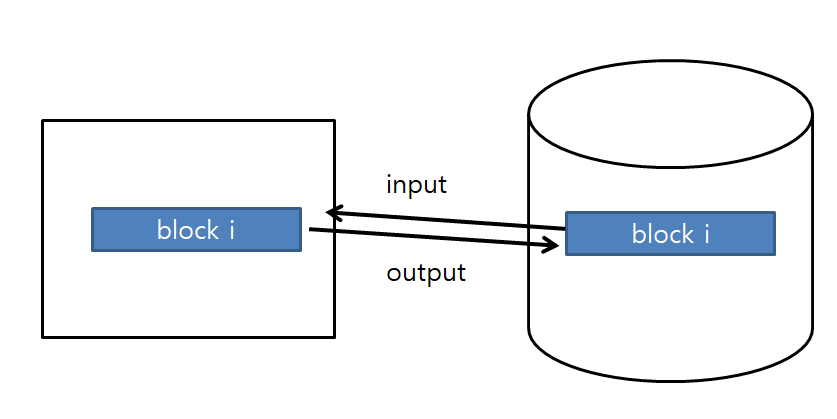
in-place updateing
버퍼를 같은 위치의 disk 위치에 기록 (overwrite)
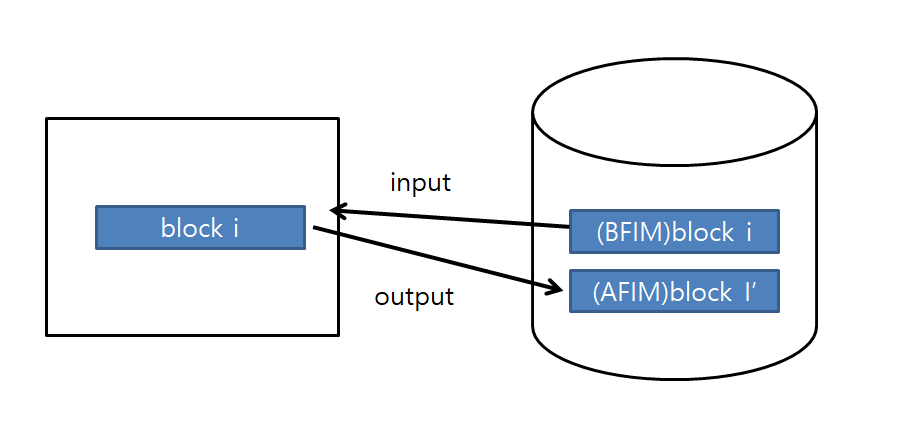
shadowing
버퍼를 disk의 다른 위치에다 사본 생성.
한 data에 대한 여러 버전을 가질 수 있다.
WAL (Write - ahead loggin)
WAL을 사용하는 시스템엔, 모든 수정 사항들은 로그에 기록된다.
복구를 위해서는 다음 log 정보가 필요하다.
Redo
커밋이 된 후 에러가 발생했을 때, 해당 트렌젝션을 다시 실행.
트렌젝션을 재수행만 하면 되기 때문에 큰 문제는 없다.
Undo
커밋이 되지 않았기 때문에, 처음부터 다시 해야 한다.
해당 트렌젝션의 모든 Redo, Undo 레코드가 디스크에 기록될 때 까지,
트랜젝션은 커밋을 할 수 없다.
즉, 로그 사항을 다 반영하기 전 까진, 커밋을 할 수 없다.
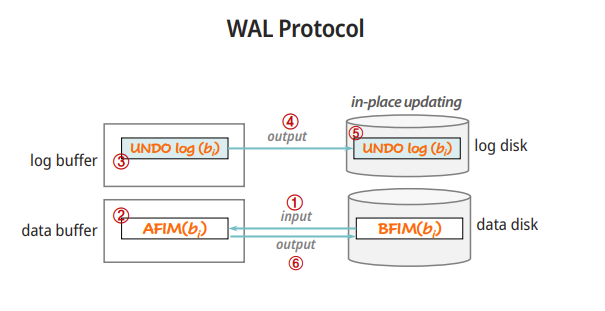
Steal/No-steal
트렌젝션이 commit되지 않은 상황에서, 데이터를 디스크에 저장하는 것에 대한 정책
steal : 허가
No-steal : 커밋 전까진 디스크로 내보내기 X

Force/No-force
트랜젝션이 commit 된 상황에서, 데이터를 디스크에 저장하는 것에 대한 정책
Force : commit이 되면, 바로 db에 적용
No-force : 커밋 돼도, 나중에 넣어도 됨

Redo
커밋 후 에러가 나는 상황에 적용.
다음 예시를 보자.

log1에선, 커밋이 안 된 상태에서 날아간 거니, 별 다른 조치는 하지 않는다.
log2에선, T1이 커밋되기 전 작업들을 redo 한다.
마찬가지로, log3도 commit 이전 작업들만 redo 해준다.
Undo
커밋 전 에러가 발생한 상황에 적용.
old 값으로 되돌아간다.
다음 예시를 보자.
실제 DB에 커밋하는건 DBMS 맘이지만, DBMS가 관여하지 않는다고 가정한다.
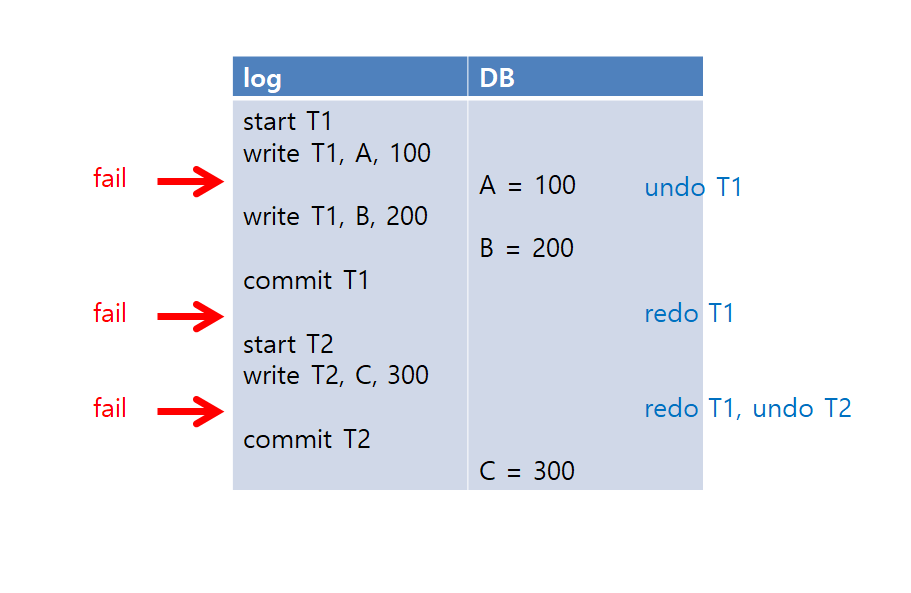
log를 보면, 첫 번째 fail에선 commit이 되지 않았으므로, T1은 undo가 되고,
두 번째 fail에선, commit이 일어난 후에 발생한 상황이니, T1은 redo를 해준다.
마지막 fail에선, T1은 커밋이 끝난 후고, T2는 커밋이 안 됐으니,
T1은 redo를 하고, T2는 undo를 한다.
CheckPoint
위의 Undo 예시를 보면,
T1같은 경우 커밋된지 한참 됐는데, abort가 나면 redo를 해줘야 하기 때문에,
복구 비용이 커지게 된다.
이를 Check Point 기능으로 해결할 수 있는데,
abort가 날 시, Check Point 이전 작업들은 redo할 필요가 없으며,
이후 작업들만 Redo, Undo 해주면 된다.
Check Point 갱신은 일정 시간마다, 아니면 일정 commit 마다 할 수 있다.
deferred update(지연 업데이트)관점에서 예시를 보자.

다음 log를 설명하면 다음과 같다.
T1은 Checkpoint 지점 전에 commit 됐으니, 조치를 취하지 않는다.
T2는, Checkpoint 전에 commit 됐으니, Redo를 한다.
T3도 T2와 마찬가지.
T4와 T5는 commit되지 않았으므로 Cancle을 한다.
반대로, immediate update라면, Undo를 해준다.
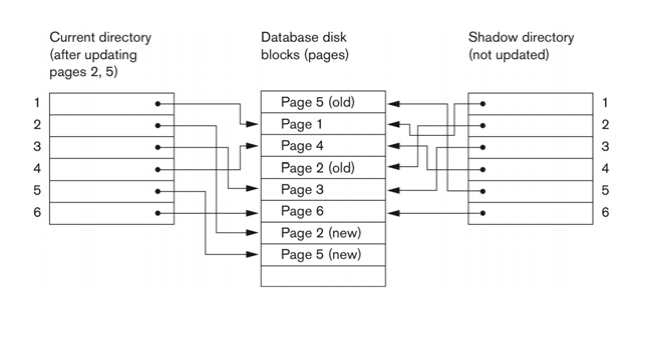
Shadow Paging
로그를 사용하지 않는 기법으로,
disk의 page를 사용한다.
page를 current, shadow 페이지 둘로 나눈다.
shadow 페이지는 DB의 old Page를 가리키고,
current 페이지는 DB의 new Page를 가리킨다.
트랜젝션이 commit되면, 기존 shadow page는 사라지고,
기존 current page가 그 자리를 대신한다.
(새로운 page가 나오면, 이 current page가 shadow page가 된다.)
Shadow page 이점은 다음과 같다.
1. 로그 레코드 과부하 없음
2. crash로부터 데이터 복구 빠름
3. redo, undo 작업 불필요
단점은 다음과 같다.
1. 데이터 분산화(Data fragmentation)
2. 가비지 컬렉션
Recovery In Multi DB
다중 데이터베이스 트렌젝션은 여러 DB에 접근이 필요하다.
원자성을 유지하기 위해, two-level recovery 매커니즘이 사용되는데
구조는 다음과 같다.
- global recover manager : coordinator라고도 하며, 처음 트랜젝션이 시작되는 사이트
- local recovery manager : log와 table 관리
coordinator 는 two-phase commit protocol을 따른다.
two-phase commit protocol
다음 구성도를 보자.
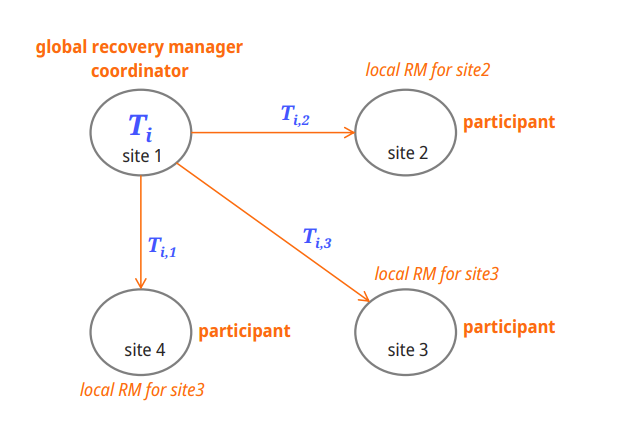
T1이 coordinator고, 그 외 site는 participant이다.
성공적인 commit을 위해선, coordinator는 participant들에게 commit 준비를 신호를 보낸다.
모든 participant가 준비가 됐다면, coordinator는 자신의 DB에 commit을 한 뒤,
participant들에게 commit을 해도 좋다는 응답을 보낸다.
이를 이중 two-phase-commit (이중 커밋)이라고 한다.
'학교 > 데이터베이스' 카테고리의 다른 글
| 18. SQL-DDL (0) | 2020.12.10 |
|---|---|
| 17. 데이터베이스 보안 (0) | 2020.12.10 |
| 15. Dead lock (0) | 2020.12.10 |
| 14. Concurrency Control (2) | 2020.12.10 |
| 13. serialize schedule (0) | 2020.12.07 |

