업데이트 내역
2023.12.23 클러스터링, 논 클러스터링 설명 개선
레코드 검색 속도를 높이는데 사용.
3가지 유형이 있다.
1. Primary Index
2. Clustering Index
3. Secondary Index (보조키로 검색하는 방법)
Primary Index
정렬된 Field에 대한 Index, 중복을 허용하지 않는다.
필드 구성은 다음과 같다.
<K(i), P(i)>
K : Ordering Key Field (PK)
정렬된 Key Feild.
P : 디스크 블록 포인터
데이터 블록당 Index Entry는 1개
대표 레코드라 하고 Anchor Record라고도 한다.
작동 방식
P(i)가 가리키는 블록으로 접근해, 그 안에서 K(i)의 위치를 찾는다.

PK가 없으면 어떻게 될까?
테이블에 PK가 존재하지 않을 수 있다.
이 경우 DBMS가 자체적으로 PK를 만든다.
하지만, PK를 명시한 것에 비해 성능이 많이 떨어진다. 테이블을 만든다면 PK를 꼭 걸어두자.
PK는 어떤 것에 걸면 좋을까?
고유하면서 의미가 없는 값
1, 2, 3... 같이 별 의미없이 순서만 매기는 칼럼이 가장 적합하고
주민등록번호, 계좌번호같이 고유하지만 의미가 있는 칼럼엔 쓰면 안 된다.
예전엔 주민등록번호가 고유한 값이니 PK로 쓰는 사이트들이 있었다.
이 주민번호는 변경될 수 있고 개인정보 보호법이 생기면서 주민등록번호를 수집, 저장할 수 없게 됐다.
이때, 주민등록번호를 PK로 쓴 곳에서는... 많은 고생을 했다고 한다.
인덱스의 종류
Dense Index(밀집 인덱스) : 데이터 레코드 각각에 하나의 Entry가 만들어진 Index
하지만, 모든 키를가지고 있기는 어렵다.
보조키 검색이(Secondary Indexs) 여기에 쓰인다.
Sparse Index(희소 인덱스) : 데이터 블록마다 하나의 Entry 가짐
적은 공간을 사용하지만, 밀집 인덱스에 비해 레코드 key를 찾는데 시간이 오래 걸린다.
PK가 여기에 쓰인다.
예시
unspanned 방식의 환경에서,
300,000 개의 레코드(record size = 100bytes)가 블럭에 저장돼 있을 때(Block size = 4096 bytes)
bfr = B/R = 4096/100 = 40 (나머지 공간 버림)
따라서, 블록당 40개의 레코드가 있고,
블럭의 개수는
B = r/bfr = 300,000 / 40 = 7500
7500개의 블록이 있다.
이를 이진탐색으로 record를 찾는다면 접근하는 블록 개수는
log2^B = log2^7500 = 13
최대 13개의 블록에 접근해야 원하는 record를 찾을 수 있다.
Primary Index를 적용한다면?
V(ordering Key field) = 9Bytes
P(block pointer) = 6Bytes
R(인덱스 파일의 레코드 하나 크기) = 9 + 6 = 15Bytes
Block size가 4096Bytes이므로,
bfr = 273 = 4096/15, Block당 273개의 entry가 있다.
블록이 7500개가 있으므로,
r/bfr = 7500/273 = 28
인덱스 블록의 개수는 28개를 갖는다.
이를 토대로 이진 탐색으로 원하는 record를 찾는다면
log2^b = log2^28 = 4.xxx
최대 5번의 블록 접근이 발생한다.
여기서 5번의 블록 접근은 Index File안에서 일어나는 것이고,
데이터 접근 비용 1번이 무조건 일어나게 된다.
따라서 총 6번의 블록 접근이 발생하고,
위의 방식에 비해 50% 이상 효율차이가 발생한다.
그림으로 정리하자면 다음과 같다.
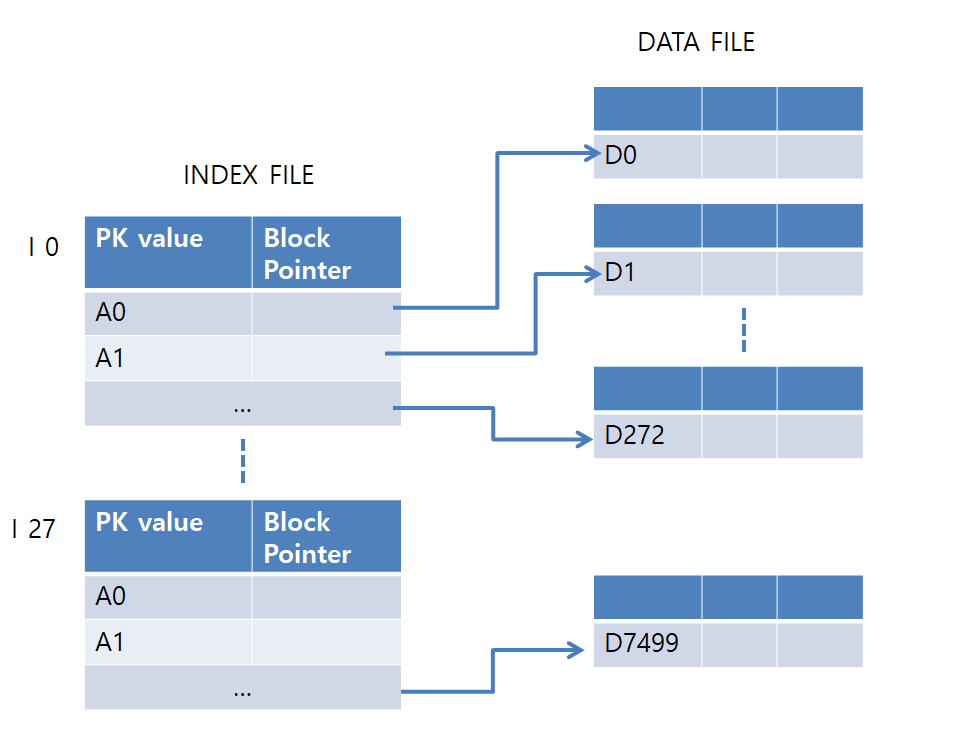
만약, INDEX가 없다면, 7500개의 DATA BLOCK에 접근해야 해서
log2^7500 의 탐색 시간이 발생하고,
INDEX가 있다면, 28개의 INDEX BLOCK에만 접근하면 되므로,
log2^28 + 1(데이터 접근 비용) 의 탐색 시간이 발생한다.
Clustering Indexes
데이터를 물리적으로 정렬하는 방식
테이블당 한 개의 클러스터링 인덱스를 적용할 수 있으며, 원하는 컬럼에 걸면 된다.
재정렬을 하려면 내가 직접 명령어를 입력해야 한다.
WHERE 절에 BETWEEN같이 범위 조회가 많은 경우 유리하다.
삽입, 삭제, 수정 빈도가 적은 정적인 테이블에 유리하다.
왜 유리할까?
I/O 비용이 감소한다.
디스크 블록을 탐색할 때마다 I/O 탐색 횟수가 증가한다. (캐시 고려 X)예를 들어, id가 1~3 까지의 레코드를 찾는데 정렬돼있지 않다면 최악의 경우 3번의 I/O가 발생한다.
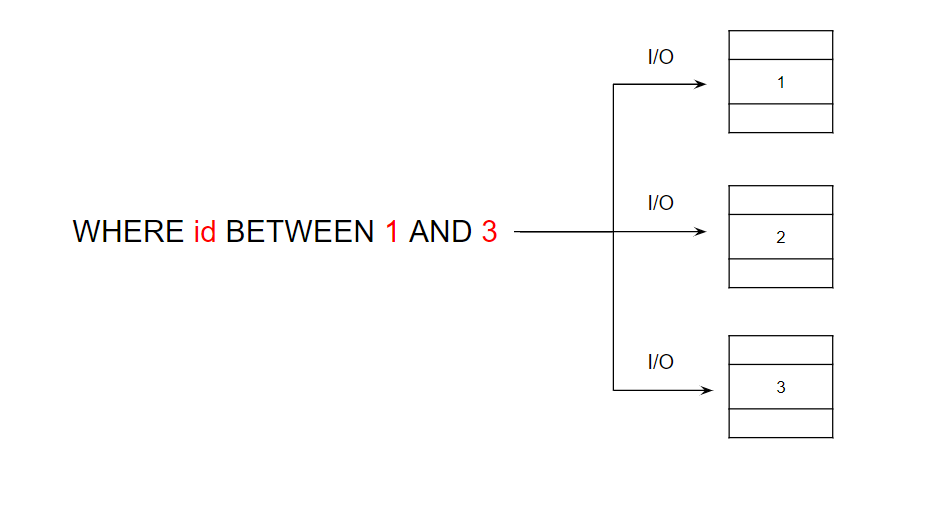
id 칼럼에 클러스터링 인덱스를 적용한다면, 다음 그림과 같이 한 번의 I/O 탐색으로 필요한 데이터를 가져올 수 있다.

레코드가 여러 블록에 걸쳐 저장된다면?
2가지 방식이 있다.
1. 다음 블록에 저장 (빈 공간 발생)
2. 필요한 만큼 채우고 다음 블록의 entry 저장 (I/O 비용 증가)

Secondary Index (Non-Clustering Index)
클러스터링 인덱스와 다음 차이가 있다.
- 데이터를 물리적으로 정렬 X
- 한 테이블에 여러 개의 논 클러스터링 인덱스를 가질 수 있다.
인덱스는 어떤 자료구조를 쓰는지에 따라 다르다. 일반적으로 B-Tree 기반 자료구조를 사용한다.
논 클러스터링 인덱스를 사용하면 칼럼들을 logN 으로 찾을 수 있지만, 다음 문제가 있다.
- 과도하게 적용할 경우 쿼리 옵티마이저 성능 ↓
(테이블당 3 ~ 4개를 권장한다.) - 저장공간 차지
데이터 3억개 테이블의 정수형 컬럼 기준 약 440MB의 인덱스 트리가 생겼다. - I/O 비용 증가
인덱스 페이지와 데이터 페이지가 구분돼 있어(B+Tree 기준) 데이터에 바로 접근하는 클러스터링 인덱스에 비해 탐색 비용이 크다. - 삽입, 삭제, 수정이 많으면 부하 증가
트리를 조정하는 비용이 크다.
특히, 삭제 비용이 매우 커서 레코드를 지울 때 물리적으로 지우는게 아니라 삭제 유무란 칼럼을 만들어 ON/OFF 식으로 관리하고, 주기적으로 다른 테이블로 이전한다.
중복된 값이 있다면?
일부 칼럼은 조회가 자주 발생하지만, 중복된 키가 있을 수 있다.
이럴 떄 해당 키를 모아둔 자료구조를 만들어 내부에서 이분탐색 같은 과정을 거친다.
즉, 간접 참조를 하나 더 만든다.
정리
index field가 key이면 Primary Index
index field가 nonkey면, secondary Index
| Index 타입 | Index Entry 수 | Dense? | Block Anchoring |
| Primary | data 파일의 블록 수 | Nondense | NO |
| Clustering | distinct Index 필드 값 수 | Nondense | YES OR NO |
| Secondary(key) | data file의 record 수 | dense | NO |
| Secondary(nonkey) | record수 또는 distinct record 수 |
Dense or Nondense | NO |
'학교 > 데이터베이스' 카테고리의 다른 글
| 11. B+-tree (0) | 2020.12.06 |
|---|---|
| 10. B-Tree (0) | 2020.12.06 |
| 8. RAID (0) | 2020.12.06 |
| 7. File (0) | 2020.12.06 |
| 6. 정규화 (0) | 2020.12.05 |



